
4 Chapter 4. Proteins and Translation
Albert B. Flavier
CHAPTER OUTLINE
_______________________________________________
4.2 Ribosomes – the protein synthesis machinery
4.3 Steps in Protein Synthesis
4.4 Levels of Protein Structure
4.6 Protein Analysis Techniques
Learning Objectives
By the end of this section, you will be able to:
- Describe the genetic code and explain the different properties of codons
- Explain the process of translation and the functions of the molecular machinery involved in translation
- Compare and contrast translation in prokaryotes and eukaryotes
- Describe the four levels of protein structure
- Describe how proteins are secreted
- Describe different protein analysis techniques
The synthesis of proteins consumes more of a cell’s energy than any other metabolic process. In turn, proteins account for more mass than any other macromolecule of living organisms. They perform virtually every function of a cell, serving as both functional (e.g., enzymes) and structural elements. The process of translation, or protein synthesis, the second part of gene expression, involves the decoding by a ribosome of an mRNA message into a polypeptide product.
4.1 The Genetic Code
Translation of the mRNA template converts nucleotide-based genetic information into the “language” of amino acids to create a protein product. A protein sequence consists of 20 commonly occurring amino acids. Each amino acid is defined within the mRNA by a triplet of nucleotides called a codon. The relationship between an mRNA codon and its corresponding amino acid is called the genetic code.
The three-nucleotide code means that there is a total of 64 possible combinations (43, with four different nucleotides possible at each of the three different positions within the codon). This number is greater than the number of amino acids; therefore, a given amino acid is encoded by more than one codon (Fig. 4.1). This redundancy in the genetic code is called degeneracy. Typically, whereas the first two positions in a codon are important for determining which amino acid will be incorporated into a growing polypeptide, the third position, called the wobble position, is less critical. In some cases, if the nucleotide in the third position is changed, the same amino acid is still incorporated.
Whereas 61 of the 64 possible triplets code for amino acids, three of the 64 codons do not code for an amino acid; they serve to terminate protein synthesis, releasing the polypeptide from the translation machinery. These are called stop codons or nonsense codons. Another codon, AUG, also has a special function. In addition to specifying the amino acid methionine, it also typically serves as the start codon to initiate translation. The reading frame, the way nucleotides in mRNA are grouped into codons, for translation is set by the AUG start codon near the 5’ end of the mRNA. Each set of three nucleotides following this start codon is a codon in the mRNA message.
The genetic code is nearly universal. With a few exceptions, virtually all species use the same genetic code for protein synthesis, which is powerful evidence that all extant life on earth shares a common origin. However, stop codons can code for some unusual amino acids such as selenocysteine and pyrrolysine have been observed in certain archaea and bacteria.
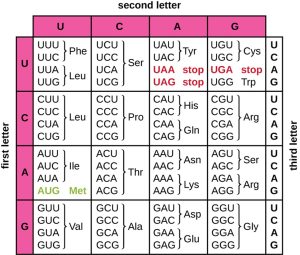
Figure 4.1. The genetic code for translating each nucleotide triplet codon in mRNA into an amino acid or serving as translation termination signal. The first letter of a codon is shown vertically on the left, the second letter of a codon is shown horizontally across the top, and the third letter of a codon is shown vertically on the right. (credit: modification of work by National Institutes of Health). CC BY-SA 4.0 from Parker et al.
4.2 Ribosomes – the Protein Synthesis Machinery
In addition to the mRNA template, many molecules and macromolecules contribute to the process of translation. The composition of each component varies across taxa; for instance, ribosomes may consist of different numbers and sizes of ribosomal RNAs (rRNAs) and polypeptides depending on the organism. However, the general structures and functions of the protein synthesis machinery are comparable from bacteria to plants to human cells. Translation requires the input of an mRNA template, ribosomes, tRNAs, and various enzymatic factors.
Ribosomes
A ribosome is a complex macromolecule composed of catalytic rRNAs (called ribozymes) and structural rRNAs, as well as many distinct polypeptides. Mature rRNAs make up approximately 50% of each ribosome. Prokaryotes have 70S ribosomes; eukaryotes have 80S ribosomes in the cytoplasm and on surfaces of the rough endoplasmic reticulum, and 70S ribosomes in mitochondria and chloroplasts. Ribosomes dissociate into large and small subunits when they are not synthesizing proteins and reassociate during the initiation of translation. In E. coli, the small subunit is described as 30S (which contains the 16S rRNA subunit), and the large subunit is 50S (which contains the 5S and 23S rRNA subunits), for a total of 70S (Svedberg units are not additive). Eukaryote ribosomes have a small 40S subunit (which contains the 18S rRNA subunit) and a large 60S subunit (which contains the 5S, 5.8S and 28S rRNA subunits), for a total of 80S. The small subunit is responsible for binding the mRNA template, whereas the large subunit binds tRNAs (discussed in the next subsection).
Each mRNA molecule is simultaneously translated by many ribosomes all reading the mRNA from a 5’ to 3’ direction and synthesizing the polypeptide from the N terminus to the C terminus. The complete structure containing an mRNA with multiple associated ribosomes is called a polyribosome (or polysome). In both bacteria and archaea, before transcriptional termination occurs, each protein-encoding transcript is already being used to begin synthesis of numerous copies of the encoded polypeptide(s) because the processes of transcription and translation can occur concurrently (co-transcriptional translation), forming polyribosomes (Fig. 4.2). Co-transcriptional translation) can occur simultaneously because both transcription and translation occur in the same 5’ to 3’ direction, they both occur in the cytoplasm of the cell, and because the RNA transcript does not have to undergo further post-transcriptional processing once it is transcribed. This allows a prokaryotic cell to respond very quickly to an environmental signal that would require synthesis of new proteins. In contrast, in eukaryotic cells, simultaneous transcription and translation is not possible because transcription and mRNA processing occurs in the nucleus, while translation begins only once the mRNA is transported into the cytoplasm.
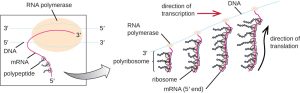
Figure 4.2. In prokaryotes, multiple RNA polymerases can transcribe a single bacterial gene while numerous ribosomes concurrently translate the mRNA transcripts into polypeptides. In this way, a specific protein can rapidly reach a high concentration in the bacterial cell. CC BY-SA 4.0 from Parker et al.
Transfer RNAs
Transfer RNAs (tRNAs) are structural RNA molecules and, depending on the species, many different types of tRNAs exist in the cytoplasm. Bacterial species typically have between 60 and 90 types, i.e., more than one tRNA can carry the same amino acid. Serving as adaptors, each tRNA type binds to a specific codon on the mRNA template and adds the corresponding amino acid to the polypeptide chain. Therefore, tRNAs are the molecules that actually “translate” the language of RNA into the language of proteins. As the adaptor molecules of translation, it is surprising that tRNAs can fit so much specificity into such a small package. The tRNA molecule interacts with three factors: aminoacyl tRNA synthetases, ribosomes, and mRNA.
Mature tRNAs take on a three-dimensional structure when complementary bases exposed in the single-stranded RNA molecule hydrogen bond with each other (Fig. 4.3). This shape positions the amino-acid binding site, called the CCA (cytosine-cytosine-adenine) binding end at the 3’ end of the tRNA, and the anticodon at the other end. The anticodon is a three-nucleotide sequence that hydrogen bonds with an mRNA codon through complementary base pairing.
An amino acid is added to the CCA end of a tRNA molecule through the process of tRNA “charging,” during which each tRNA molecule is linked to its correct or cognate amino acid by a group of enzymes called aminoacyl tRNA synthetases. At least one type of aminoacyl tRNA synthetase exists for each of the 20 amino acids. During this process, the amino acid is first activated by the addition of adenosine monophosphate (AMP) and then transferred to the tRNA, making it a charged tRNA, and AMP is released.
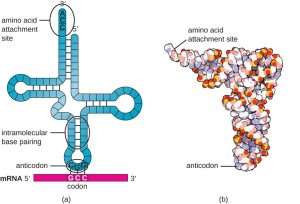
Figure 4.3 (a) After folding caused by intramolecular base pairing, a tRNA molecule has one end that contains the anticodon, which forms hydrogen bonds with the complementary mRNA codon, and the CCA amino acid binding end. (b) A space-filling model is helpful for visualizing the three-dimensional shape of tRNA. CC BY-SA 4.0 from Parker et al.
4.3 Steps in Protein Synthesis
Translation is similar in prokaryotes and eukaryotes and occurs in three stages: Initiation, elongation and termination.
Initiation
The initiation of protein synthesis begins with the formation of an initiation complex (Fig. 4.4). In E. coli, this complex involves the small 30S ribosome, the mRNA template, three initiation factors (IF-1, IF-2 and IF-3) that help the ribosome assemble correctly, guanosine triphosphate (GTP) that acts as an energy source, and a special initiator tRNA carrying N-formyl-methionine (fMet-tRNA). In E. coli mRNA, a leader sequence upstream of the first AUG codon, called the Shine-Dalgarno sequence (also known as the ribosomal binding site, AGGAGG), interacts through complementary base pairing with the 16SrRNA component of the 30S ribosome (Fig. 4.5). This interaction anchors the 30S subunit at the correct location on the mRNA template. There are three tRNA binding sites on the 30S subunit – the exit (E), peptidyl (P), and acceptor (A) sites. The anticodon of the initiator f-Met-tRNA (UAC) H-bonds with the start codon, AUG, of the mRNA positioned at the P site (Fig. 4.4). Because of its involvement in initiation, fMet is inserted at the N terminus of every polypeptide chain synthesized by E. coli. At this point, the initiation factors leave the 30S subunit and the 50S subunit then binds to the initiation complex, forming an intact ribosome.
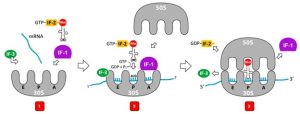
Figure 4.4 Initiation of translation. 1. Initiation of translation in bacteria requires the small ribosomal subunit (30S), the mRNA, the initiator tRNA carrying N-formyl-methionine with UAC anticodon, and initiation factors. 2. IF-3 binds to the small SU to keep the large subunit (50S) from binding to the small SU until all the other components are in place. IF-1 binds to the A site to prevent the fMet-tRNA from binding to the A site. IF-2 guides the fMet-tRNA to the P site and IF-3 and IF-1 leaves the complex. 3. The 50S subunit associates with the 30S to form the 70S initiation complex, IF-2 hydrolyses GTP to GDP and GDP-IF-2 is released. Attribution: CC BY SA 3.0 by User07 via WikiCommons

Figure 4.5. Alignment of Shine-Dalgarno sequences from the translation initiation regions of six E. coli genes. CC-SA-4.0 from Ahern.
In eukaryotes, translation initiation complex formation is similar to bacteria with the following differences:
- The initiator tRNA is a different specialized tRNA carrying methionine, called Met-tRNAi
- Instead of binding to the mRNA at the Shine-Dalgarno sequence, the eukaryotic initiation complex, which includes the 40S ribosome and initiation factors, recognizes and binds to the 5’ cap of the eukaryotic mRNA, then scans along the mRNA in the 5’ to 3’ direction until it encounters a consensus Kozak sequence (Fig. 4.6) which includes an AUG start codon. Another initiation factor brings the Met-tRNAi to the AUG at the P-site. The initiation factors then dissociate from the ribosome and the 60S subunit binds to the complex of Met-tRNAi, mRNA, and the 40S subunit.

Figure 4.6. A diagram derived from counts of the bases in the translation initiation region from all human genes. Each letter is written in proportion to its frequency of occurrence. The letters are stacked together in a sequence logo. The most significantly biased bases are -3 (A) and +4 (G). CC BY SA 3.0 by TransControl.
Elongation
In prokaryotes and eukaryotes, the basics of elongation of translation are the same. In E. coli, the binding of the 50S ribosomal subunit to produce the intact ribosome forms three functionally important ribosomal sites: The A site (aminoacyl or acceptor site) binds incoming charged aminoacyl tRNAs. The P site (peptidyl) binds charged tRNAs carrying amino acids that have formed peptide bonds with the growing polypeptide chain but have not yet dissociated from their corresponding tRNA. The E site (exit) releases uncharged (empty) tRNAs so that they can be recharged with free amino acids.
There are three main processes that take place during elongation (Fig. 4.7): 1) Codon recognition, 2) Peptide bond formation, and 3) Translocation. Codon recognition involves the pairing of the anticodon of incoming aa-tRNAs with the mRNA codon in the A site. Peptide bond formation between an amino acid (or growing peptide) attached to a tRNA on the P site and the amino acid on the tRNA in the A site is catalyzed by the 23S subunit in the 50S ribosome.
Elongation proceeds with single-codon movements of the ribosome each called a translocation event. During each translocation event, the charged tRNAs enter at the A site, then is shifted by the ribosome to the P site, and then finally to the E site for removal. Ribosomal movements, or steps, are induced by conformational changes that advance the ribosome by three bases in the 3’ direction and is catalyzed by a translation elongation factor (EF-G). Peptide bonds form between the amino group of the amino acid attached to the A-site tRNA and the carboxyl group of the amino acid attached to the P-site tRNA. In bacteria, the formation of each peptide bond is catalyzed by 23SrRNA, an RNA-based ribozyme that is integrated into the 50S ribosomal subunit which has peptidyl transferase activity. The amino acid bound to the P-site tRNA is also linked to the growing polypeptide chain. As the ribosome steps across the mRNA, the former P-site tRNA enters the E site and is expelled from the ribosome. The A-site tRNA carrying the assembled peptide moves to the P site, rendering the A site empty and ready to accept the next aa-tRNA that is carried by the elongation factor, EF-Tu. Several of the steps during elongation, including binding of a charged aminoacyl tRNA to the A site and translocation, require energy derived from GTP hydrolysis, which is catalyzed by specific elongation factors. Amazingly, the E. coli translation apparatus takes only 0.05 seconds to add each amino acid, meaning that a 200 amino-acid protein can be translated in just 10 seconds.
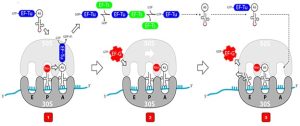
Figure 4.7. Elongation phases. 1) Codon recognition is when incoming aa-tRNA with complementary anticodon enters and binds to the mRNA codon on the A-site. The aa-tRNA is guided by EF-Tu-GTP which releases the tRNA upon GTP hydrolysis to GDP. 2) Peptidyl transferase (23S rRNA) in the 50S catalyzes the formation of peptide bond between the amino acid on the P site tRNA and the amino acid on the A-site tRNA. 3) Translocation is when the ribosome moves one codon towards the 3’ end of the mRNA and is aided by EF-G-GTP where GTP gets hydrolyzed to GDP. EF-G-GTP moves the A-site tRNA to the P site. The empty tRNA ends up in the E site from which it exits the ribosome, the tRNA with the assembled peptide is moved to the P-site from the A site. The A-site becomes unoccupied and is ready to accept the next aa-tRNA. Modified from User07 (CC BY SA 3.0)
Termination
The termination of translation occurs when a nonsense codon (UAA, UAG, or UGA) is encountered for which there is no complementary tRNA. On aligning with the A site, these nonsense codons are recognized by release factors (RF) in prokaryotes and eukaryotes that result in the hydrolysis of the P-site polypeptide and the assembled peptide getting detached and released from the P-site tRNA. In E. coli, RF1- and RF-2 bind to specific nonsense codons in the A site, while RF-3-GTP facilitates release of RF-1 from the ribosome after translation termination; RF2 can dissociate spontaneously. The small and large ribosomal subunits then dissociate from the mRNA and from each other after which they are recruited almost immediately into another translation initiation complex.
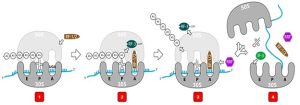
Figure 4.8. Termination of translation. 1) A stop codon (UGA, UAG, or UAA) becomes situated in the A site of the small ribosome subunit. 2) A release factor (RF1 or RF2) associates with the stop codon. 3) The assembled peptide detaches from the P-site tRNA. 4) the translated protein, ribosomal subunits, mRNA, and tRNA disassemble. Attribution: CC BY SA 3.0 by User07 via WikiCommons.
Watch the video on translation below. The video does not mention the translation factors. As you watch the video, try to recall the roles of the different translation factors and ribosome components as described in the preceding text.
There are several key features that distinguish prokaryotic gene expression from that seen in eukaryotes. These are illustrated in Fig. 4.9 and listed in Fig. 4.10.
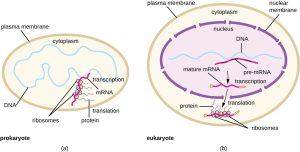
Figure 4.9. (a) In prokaryotes, the processes of transcription and translation occur simultaneously in the cytoplasm, allowing for a rapid cellular response to an environmental cue. (b) In eukaryotes, transcription is localized to the nucleus and translation is localized to the cytoplasm, separating these processes and necessitating RNA processing for stability. CC BY-SA 4.0 from Parker et al.
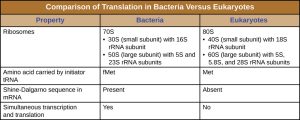
Figure 4.10. Comparison of translation in bacteria versus eukaryotes. CC BY-SA 4.0 from Parker et al.
*Sections 4.1 to 4.3 are mostly modified from Parker et al.
4.4 Levels of Protein Structure
The significance of the unique sequence, or order, of amino acids, known as the protein’s primary structure, is that it dictates the 3-D conformation the folded protein will have. This conformation, in turn, will determine the function of the protein. We shall examine protein structure at four distinct levels (Fig 4.11): 1) how sequence of the amino acids in a protein (primary structure) gives identity and characteristics to a protein; 2) how local interactions between one part of the polypeptide backbone and another affect protein shape (secondary structure); 3) how the polypeptide chain of a protein can fold to allow amino acids to interact with each other that are not close in primary structure (tertiary structure); and 4) how different polypeptide chains interact with each other within a multi-subunit protein (quaternary structure).
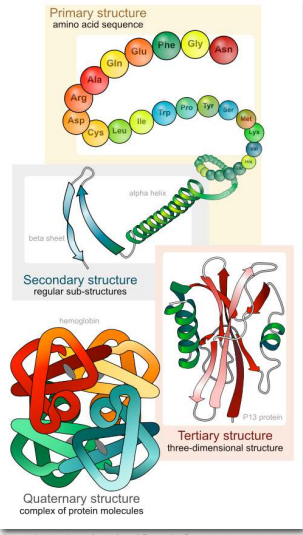
At this point, we should provide a couple of definitions. We use the term polypeptide to refer to a single polymer of amino acids. It may or may not have folded into its final, functional form. The term protein is sometimes used interchangeably with polypeptide, as in “protein synthesis”. It is generally used, however, to refer to a folded, functional molecule that may have one or more subunits (made up of individual polypeptides). Thus, when we use the term protein, we are usually referring to a functional, folded polypeptide or peptides. Structure is essential for function. If you alter the structure, you alter the function – usually, but not always, this means you lose all function. For many proteins, it is not difficult to alter the structure.
Proteins are flexible, not rigidly fixed in structure. As we shall see, it is the flexibility of proteins that allows them to be amazing catalysts and allows them to adapt to, respond to, and pass on signals upon binding of other molecules or proteins. However, proteins are not infinitely flexible. There are constraints on the conformations that proteins can adopt and these constraints govern the conformations that proteins display.
Even very tiny, subtle changes in protein structure can give rise to big changes in the behavior of proteins. Hemoglobin, for example, undergoes an incredibly small structural change upon binding of one oxygen molecule, and that simple change causes the remainder of the protein to gain a considerably greater affinity for oxygen that the protein didn’t have before the structural change.
The number of different amino acid sequences possible, even for short peptides, is very large. No two proteins with different amino acid sequences (primary structure) have identical overall structure. The unique amino acid sequence of a protein is reflected in its unique folded structure. This structure, in turn, determines the protein’s function. This is why mutations that alter amino acid sequence can affect the function of a protein.
Primary Structure
Primary structure is the ultimate determinant of the overall conformation of a protein. The order in which the amino acids are joined together by peptide bonds during protein synthesis starts defining a set of interactions between amino acids even as translation is occurring. That is, a polypeptide can fold even as it is being made. The order of the R-group structures and resulting interactions are very important because early interactions affect later interactions. This is because interactions start establishing structures – secondary and tertiary. If a helical structure (secondary structure), for example, starts to form, the possibilities for interaction of a particular amino acid R group may be different than if the helix had not formed (Fig. 4.12). R-group interactions can also cause bends in a polypeptide sequence (tertiary structure) and these bends can create (in some cases) opportunities for interactions that wouldn’t have been possible without the bend or prevent (in other cases) similar interaction possibilities.
Secondary Structure
As protein synthesis progresses, hydrogen bonds between amino acids close to each other begin to occur, giving rise to local patterns called secondary structure. These secondary structures include the well known α- helix and β-strands. Each structure has unique features.
α-helix. The α-helix has a coiled structure. In the α-helix, hydrogen bonds form between C=O groups and N-H groups in the polypeptide backbone that are four amino acids distant. These hydrogen bonds are the primary forces stabilizing the α-helix.
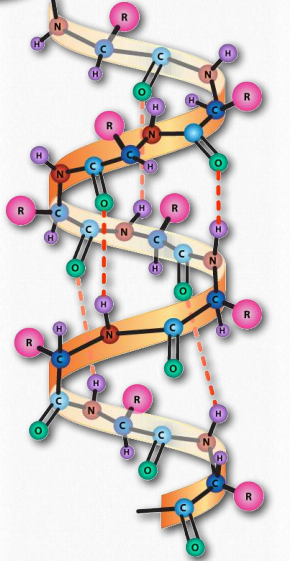
Figure 4.12. The α-helix. Hydrogen bonds (dotted lines) between the carbonyl oxygen and the amine hydrogen stabilize the structure. Image by Aleia Kim.
β strand/sheet. Rather than coils, β-strands have bends (Fig. 4.13). β-strands can be organized to form elaborately organized structures, such as sheets, barrels, and other arrangements. β-strand structures are stabilized also by formation of hydrogen bonds, but this time, in parallel strands of the peptide.

Figure 4.13. β strand. CC BY SA 4.0 from Theislikerice
Higher order β-strand structures are sometimes called supersecondary structures (Fig. 4.14), since they involve interactions between amino acids not close in primary sequence. These structures, too, are stabilized by hydrogen bonds between carbonyl oxygen atoms and hydrogens of amine groups in the polypeptide backbone. In a higher order structure, strands can be arranged parallel (amino to carboxyl orientations the same) or anti-parallel (amino to carboxyl orientations opposite of each other in Fig. 4.14), the direction of the strand is shown by the arrowhead in the ribbon diagrams).
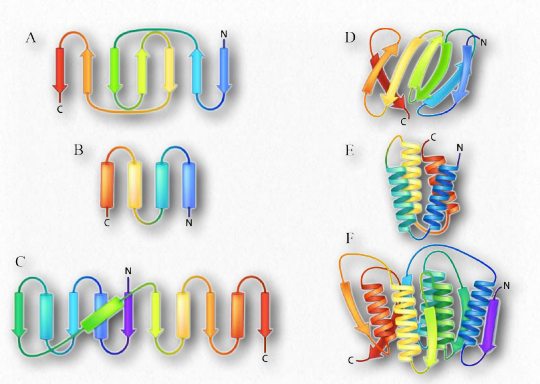
Turns are a type of secondary structure that, as the name suggests, causes a turn in the structure of a polypeptide chain. Turns give rise to tertiary structure ultimately, causing interruptions in the secondary structures (α- helices and β-strands) and often serve as connecting regions between two regions of secondary structure in a protein. Proline and glycine play common roles in turns, providing less flexibility (starting the turn) and greater flexibility (facilitating the turn), respectively.
Tertiary structure
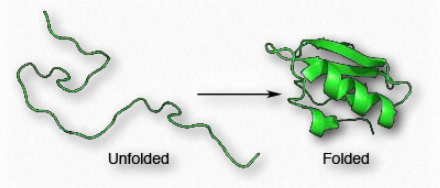
Proteins are distinguished from each other by the sequence of amino acids comprising them. The sequence of amino acids of a protein determines protein shape, since the chemical properties of each amino acid are forces that give rise to intermolecular interactions to begin to create secondary structures, such as α-helices and β-strands. The sequence also defines turns and random coils that play important roles in the process of protein folding.
Since shape is essential for protein function, the sequence of amino acids gives rise to all of the properties a protein has. As protein synthesis proceeds, individual components of secondary structure start to interact with each other, giving rise to folds that bring amino acids close together that are not near each other in primary structure (Fig. 4.15). At the tertiary level of structure, interactions among the R-groups of the amino acids in the protein, as well as between the polypeptide backbone and amino acid side groups play a role in folding. Aside from hydrogen bonds, ionic interactions, Van der Waals and hydrophobic forces, and disulfide bonds between cysteines, can all contribute to the tertiary structure.
Globular proteins
Folding gives rise to distinct 3-D shapes in proteins that are non-fibrous. These proteins are called globular. A globular protein is stabilized by the same forces that drive its formation. These include ionic interactions, hydrogen bonding, hydrophobic forces, ionic bonds, disulfide bonds and metallic bonds. Treatments such as heat, pH changes, detergents, urea and mercaptoethanol overpower the stabilizing forces and cause a protein to unfold, losing its structure and (usually) its function. The ability of heat and detergents to denature proteins is why we cook our food and wash our hands before eating – such treatments denature the proteins in the microorganisms on our hands. Organisms that live in environments of high temperature (over 50°C) have proteins with changes in stabilizing forces – additional hydrogen bonds, additional salt bridges (ionic interactions), and compactness may all play roles in keeping these proteins from unfolding.
Molecular chaperones
Cells expend energy to facilitate the proper folding of proteins. Cells use two classes of proteins known as molecular chaperones, to facilitate such folding in cells. Molecular chaperones are of two kinds, the chaperones, and the chaperonins. An example of the first category is the Hsp class of proteins. Hsp stands for “heat shock protein”, based on the fact that these proteins were first observed in large amounts in cells that had been briefly subjected to high temperatures. Hsps assist in the proper folding of polypeptides by preventing aberrant interactions that could lead to misfolding or aggregation. One Hsp, DnaK, binds to polypeptides as they emerge from ribosomes during protein synthesis. Hsps use ATP hydrolysis to stimulate structural changes in the shape of the chaperone to accommodate binding of substrate proteins.
A second class of proteins involved in assisting other proteins to fold properly are known as chaperonins. The best studied chaperonins are the GroEL/GroES complex proteins found in bacteria (Fig. 4.16). GroEL is a double-ring 14mer with a hydrophobic region. GroES is a single ring heptamer that binds to GroEL in the presence of ATP and functions as a cover over GroEL. Hydrolysis of ATP by chaperonins induce large conformational changes that affect binding of substrate proteins and their folding.
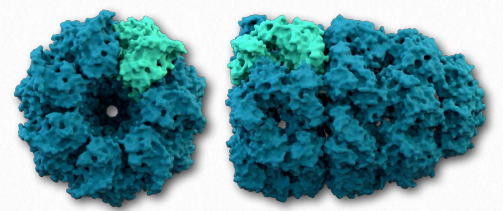
Quaternary structure
A fourth level of protein structure is that of quaternary structure. It refers to structures that arise as a result of interactions between multiple polypeptides. The units can be identical multiple copies or can be different polypeptide chains. Adult hemoglobin is a good example of a protein with quaternary structure, being composed of two identical chains called α and two identical chains called β.
Though the α-chains are very similar to the β- chains, they are not identical. Both of the α- and the β-chains are also related to the single polypeptide chain in the related protein called myoglobin. Both myoglobin and hemoglobin have similarity in binding oxygen, but their behavior towards the molecule differ significantly. Notably, hemoglobin’s multiple subunits (with quaternary structure) compared to myoglobin’s single subunit (with no quaternary structure) give rise to these differences.
Post translational modifications
During and after translation, many polypeptides need to undergo post-translational modifications before they can be biologically functional. Post-translational modifications include:
- Removal of N-terminal initiator f-Met in prokaryotes (Met in eukaryotes).
- Removal of signal sequences—short stretches of amino acids at the N or C-terminus that targets a protein for localization to the membrane or secretion to the cell exterior.
- Proper “folding” of the polypeptides and association of multiple polypeptide subunits (quaternary structure), often facilitated by chaperone proteins, into distinct three-dimensional structures. Many require the formation of intrachain and/or interchain disulfide bonds.
- Proteolytic processing of an inactive polypeptide by peptidases or proteases to release an active protein component.
- Addition of various chemical modifications (e.g., phosphorylation, methylation, lipidation or glycosylation) to certain amino acids
Improper or incomplete post-translational modification can affect the folding of the protein, its activity, stability and immunogenic property. In the manufacturing of biologics as drugs, improperly modified proteins are considered by regulatory agencies as unwanted product impurities.
*Contents of section 4.4 are adopted mainly from Ahern et al
4.5 Protein Secretion
There are several challenges to successfully attaining high levels of recombinant proteins in the cytoplasm of E. coli.
- For proteins that require disulfide bond formation for tertiary or quaternary structure, the cytoplasm is a reducing environment.
- E. coli K-12 has 72 proteases that can cleave proteins and majority of them are in the cytoplasm.
- The presence of the recombinant protein at abnormally high amounts can lead to protein aggregation and formation of inclusion bodies.
- There are insufficient levels of chaperones to assist in the proper folding of most proteins, thus leading to misfolded proteins that would have the propensity to aggregate.
- There are proteins that are toxic to E. coli when present in the cytoplasm.
To overcome the limitations on expressing proteins in the cytoplasm, increased production of many proteins has been achieved by secreting the proteins into the periplasmic space or extracellularly into the culture media. In contrast to the reducing environment of the cytoplasm, the periplasmic space favors oxidation of the sulfhydryl groups in cysteines thus leading to successful disulfide bond formation. There are also less proteases in the periplasm and in the culture media. Secretion into the culture media tends to dilute the proteins leading to enhance solubility. Toxicity is also avoided by targeting proteins outside the cell. Moreover, the lower amounts of host proteins secreted, compared to those found in the cytoplasm, facilitates downstream recombinant protein purification from the rest of the culture media components. Post translational removal of N-terminal sequences can also be achieved through secretion.
In Gram-negative bacteria, proteins are secreted into the periplasm or into the media through one of nine distinct secretion systems (Fig. 4.17) which are normally employed for secretion of pathogenicity or virulence factors or toxins, or DNA. T1SS, T3SS, T4SS and T6SS secrete proteins to the outside in one step without transient localization in the periplasm. In contrast, the SecB, SRP, and twin-arginine translocation (TAT) pathways allows transport through the inner membrane then release the proteins into the periplasm.
Several proteins (scFv, cutinase, lipase) have been successfully secreted into the media using mostly T1SS ( e.g., HylA). Disulfide bond formation takes place during protein translocation. A disadvantage of T1SS secretion is that the C-terminus signal is not cleaved and would require additional downstream steps to remove the signal.
For two-step translocation, different components of the Sec or Tat pathway have been overexpressed to facilitate secretion into the periplasm of proteins using N-terminus signal peptides. Once in the periplasm, transport through the OM and into the culture media is through T2SS, T5SS, or T7SS, or are released by chemical, mechanical, or lysozyme treatment, or a combination. Leaky mutants have also been used to increase secretion through the outer membrane.
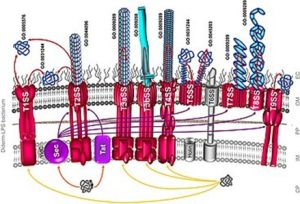
Figure 4.17. Nine distinct secretion systems through which a secreted protein can be translocated across the inner and outer membrane of Gram-negative bacteria. CP, cytoplasm; IM, inner membrane; PP, periplasm; OM, outer membrane; EC, extracellular milieu; SP, signal peptide. CC-SA 3.0 by Chagnot
Antibiotics that interfere with translation
Certain antibiotics work by interfering with translation:
- Puromycin – binds to the A site by mimicking an aa-tRNA and accepting the nascent peptide which gets detached from the peptidyl-tRNA on the P-site
- Aminoglycosides – Examples are streptomycin and kanamycin. Bind to 30S SU and interfere with proper codon recognition leading to incorporation of incorrect amino acids and non-functional proteins.
- Tetracycline – binds IF-3 and IF-1 to interfere with translation initiation and binds also to the A site to block access by incoming EF-Tu-tRNA’s during elongation.
- Chloramphenicol – binds to 23SrRNA in the 50S SU to block peptidyl transferase activity.
4.6 Protein Analysis Techniques
SDS- Polyacrylamide gel electrophoresis (SDS-PAGE)
Proteins are large macromolecules. The charge on each protein depends on its amino acid sequence. In contrast to nucleic acids, proteins are considerably smaller and the openings of the matrix of the agarose gel that is used in DNA separation are too large to effectively provide separation. Thus, gel made up of polyacrylamide, which contains smaller openings is used. To denature and linearize proteins and give them a negative charge, the anionic detergent, sodium dodecyl sulfate (SDS) is added such that the denatured proteins will get separated mainly by size. Agents like b-mercaptoethanol or dithiothreitol (DTT) can be added to reduce disulfide bonds. When subjected to an electric field, the negatively charged, linear proteins will migrate towards the anode (Fig. 4.18).
Non-denaturing gel electrophoresis
In situations where the structure and activity of the proteins need to be preserved, proteins may be resolved on so-called “native” gels in the absence of SDS. The movement of proteins through the gel will be affected by their size as well as their charge.
Figure 4.18. SDS-PAGE gels where proteins appear as blue bands when stained with Coomassie Blue and . CC BY-SA 2.0 by Helms
Isoelectric focusing
Proteins vary considerably in their charges and, consequently, in their pI values or isoelectric point, the pH at which the protein charge is zero. This can be exploited to separate proteins in a mixture. Separating proteins by isoelectric focusing requires establishment of a pH gradient in a tube containing an acrylamide gel matrix (Fig. 4.19). The pore size of the gel is large to reduce the effect of sieving based on size. Molecules to be separated are applied to the gel containing the pH gradient and an electric field is applied. Under these conditions, proteins will move according to their charge.
Positively charged molecules, for example, move towards the negative electrode, but since they are traveling through a pH gradient, as they travel through the gel, they reach a region where their charge is zero and, at that point, they stop moving. They are at that point attracted to neither the positive nor the negative electrode and are thus “focused” at their pI (Fig. 4.19). Using isoelectric focusing, it is possible to separate proteins whose pI values differ by as little as 0.01 units.
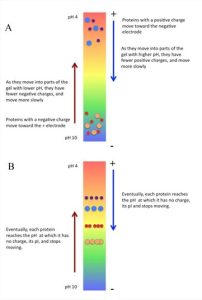
Figure 4.19. Isoelectric focusing:
A. At the start of the run;
B. At the end of the run showing that proteins stopped moving when they reach a pH on the gel where they have neutral charges. CC BY-NC-SA 4.0 by Ahern
2D gel electrophoresis
Both SDS-PAGE and isoelectric focusing are powerful techniques, but a clever combination of the two is a powerful tool of proteomics – the science of studying all of the proteins of a cell/tissue simultaneously. In 2-D gel electrophoresis, cell lysate is first prepared from the cells of interest. The proteins in the lysate are separated first by their pI, through isoelectric focusing and then by size by SDS-PAGE (Fig. 4.20).
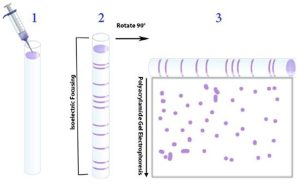
Figure 4.20. Scheme for performing 2-D gel analysis. 1) The mixture of proteins is first applied to a tube or strip. 2) isoelectric focusing is performed to separate the proteins by their pI values. 3) The gel containing the proteins separated by their pIs is turned on its side and applied along the top of a polyacrylamide slab for SDS-PAGE electrophoresis and the proteins get separated on the basis of size. Image by Aleia Kim from Ahern, et al.
The product of 2-D gel separation is shown in Fig. 4.21. The power of 2-D gel electrophoresis is that virtually every protein in a cell can be separated and appear on the gel as a spot defined by its unique size and pI. Every spot on a 2-D gel can be extracted and eluted and identified by using high throughput mass spectrometry. This is particularly powerful when one compares protein profiles between different tissues or between control and treated samples of the same tissue.

Figure 4.21. Result of 2-D gel electrophoresis separation. Spots in the upper left correspond to large positively charged proteins, whereas those in the lower right are small negatively charged ones. CC BY-NC-SA 4.0 by Ahern
Western Blots
Proteins cannot, for obvious reasons, be detected through base-pairing with a DNA probe. Protein blots, made by transferring proteins separated on a gel onto a membrane, can be probed using specific antibodies against a particular protein of interest (Fig. 4.22). Protein detection usually employs two antibodies, where the first or primary antibody is not labeled. The label is on the secondary antibody, which is designed to recognize only the first antibody in a piggyback fashion. The first antibody specifically binds to the protein of interest on the blot and the second antibody recognizes and binds to the first antibody. The second antibody commonly carries an enzyme or reagent, which in the presence of a chemical substrate, can cause a reaction to produce a color or light. In the end, if the molecule of interest is in the original mixture, it will “light” up and reveal itself on the blot. This variation on the blotting theme was dubbed a Western blot (Figure 4.22).
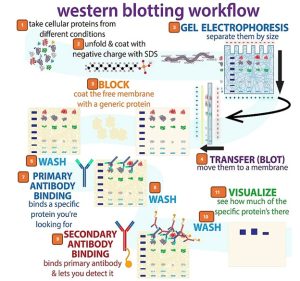
Figure 4.22 . Steps for preparing a Western blot. 1) Protein mixture is isolated. 2) Protein is denatured using SDS. 3) Proteins are separated by SDS-PAGE. 4) Proteins are transferred from gel to a membrane. 5) Membrane is blocked by using bovine serum albumin (BSA) or skim milk solution. 6) Membrane is washed to remove excess BSA or milk. 7) Membrane is incubated in solution containing the primary antibody which binds with specificity to the target protein. 8) Excess antibody is washed with buffer. 9) Membrane is incubated in solution containing the secondary antibody which binds to the primary antibody. 10) Excess secondary antibody is washed. 11) Membrane is visualized by radiography or digital imager. CC-BY SA 4.0 by Biochemlife
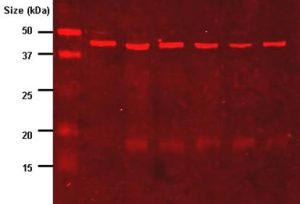
Figure 4.23. Western blot result where the imaging antibody is labelled with IR-dye which fluoresces red. A molecular weight marker is in the first gel lane. CC BY-SA 3.0 from TimVickers.
In the blots shown in Fig. 4.22 and 4.23, binding of the antibody probe to the target molecule allows one to determine whether the target protein was in the sample. Although blots are designed to be used for detection, rather than for precise quantitation, it is possible to obtain estimates of the abundance of the target molecule from densitometry measurements of signal intensity.
The sections on SDS-PAGE, 2-D gel electrophoresis, and Western blot were modified under a CC BY-NC-SA 4.0 license and authored by Kevin Ahern, Indira Rajagopal, & Taralyn Tan.
Enzyme-Linked ImmunoSorbent Assay (ELISA)
Western blot uses antibodies to detect specific proteins of interest. However, it is not very useful in quantifying the amounts of the target protein . To quantify amounts of proteins, including those that may be present in complex solutions, one widely used technique is Enzyme-Linked ImmunoSorbent Assay (ELISA). The assay is performed on a 96-well plate where reagents are immobilized or adsorbed onto. Similar to a Western blot, an enzyme is linked or conjugated to one antibody and upon addition of a chemical substrate, the resulting color or light produced in the 96-well plate is measured using a plate reader (spectrophotometer). The intensity of the color change or light is proportional to the amount of the target protein in the sample and is calculated based on a graph of the absorbance of different concentrations of a protein standard.
Watch how an ELISA is done:
Column chromatography
Column chromatography distributes and separates a mixture of chemicals into a solid and a liquid phase. The solid phase is also called the stationary phase while the liquid phase is referred to as mobile phase. The solid phase can be agarose gel or resin beads with different chemicals conjugated onto the beads. Substances get separated based on their solubility in the mobile phase and their differential interaction with the stationary phase. Chromatography can be used to separate proteins based on different properties such as size, charge, hydrophobicity or affinity to certain ligands which are attached to the stationary phase. The different types of protein chromatography are discussed in detail as part of downstream bioprocess in Chapter 10.

Figure 4.24. 1) An AKTA protein chromatography system showing the column packed with the stationary phase (red arrow) and the solutions that will get mixed to produce mobile phase with the desired properties which are tailored to the separation process (blue arrows). CC0 by Flavier. 2) Magnified view of an AKTA column with the stationary phase. Wikipedia
Additional resources:
- https://bio.libretexts.org/Bookshelves/Biotechnology/Lab_Manual%3A_Introduction_to_Biotechnology/01%3A_Techniques/1.14%3A_Column_Chromatography
- https://bio.libretexts.org/Bookshelves/Biotechnology/Encyclopedia_of_Biological_Methods_(Mattaini)/06%3A_Column_chromatography
-
https://bio.libretexts.org/Bookshelves/Biotechnology/Encyclopedia_of_Biological_Methods_(Mattaini)/32%3A_Western_blot
- ELISA (Enzyme-Linked ImmunoSorbent Assay) for qualitative and quantitative analysis of proteins.
End-of-Chapter Questions:

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}