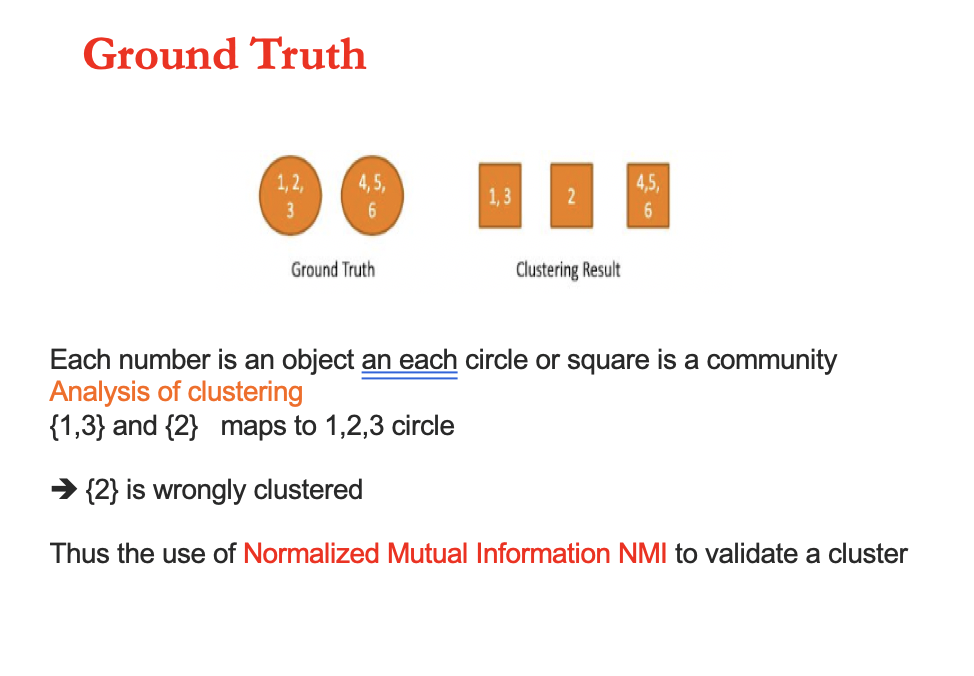
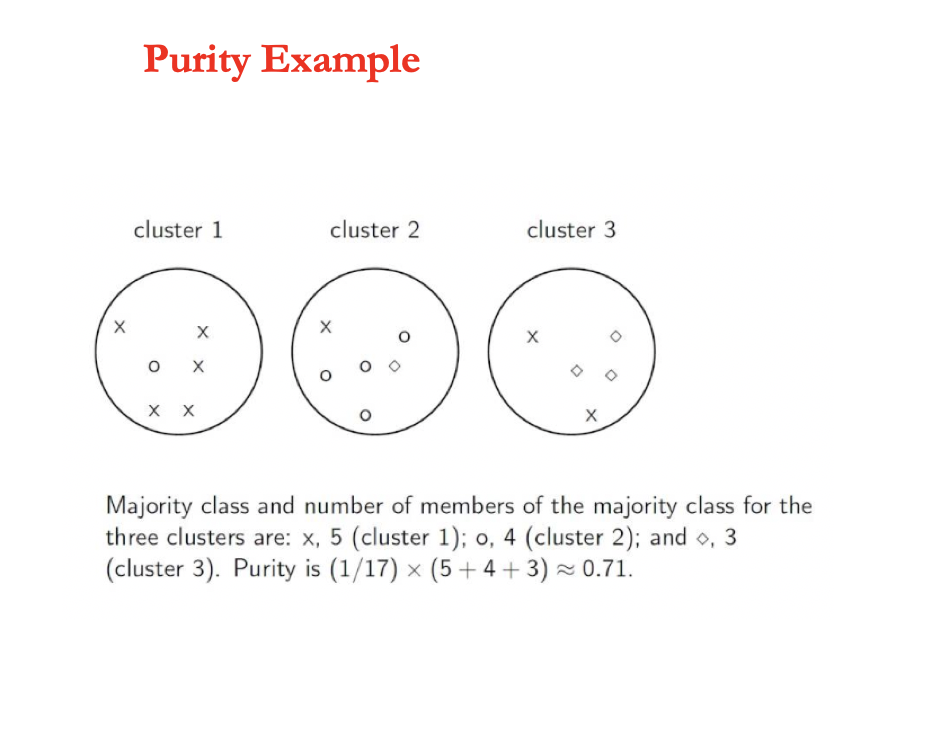
33 Clustering Metrics and Cluster Validity
Cluster analysis is finding similarities between data according to the characteristics found in the data and grouping similar data objects into clusters.

Typical applications
- As a stand-alone tool to get insight into data distribution
- As a preprocessing step for other algorithms
Dissimilarity/Similarity metric
The similarity is expressed in terms of a distance function, which is typically metric: d(i, j)
There is a separate “quality” function that measures the “goodness” of a cluster.
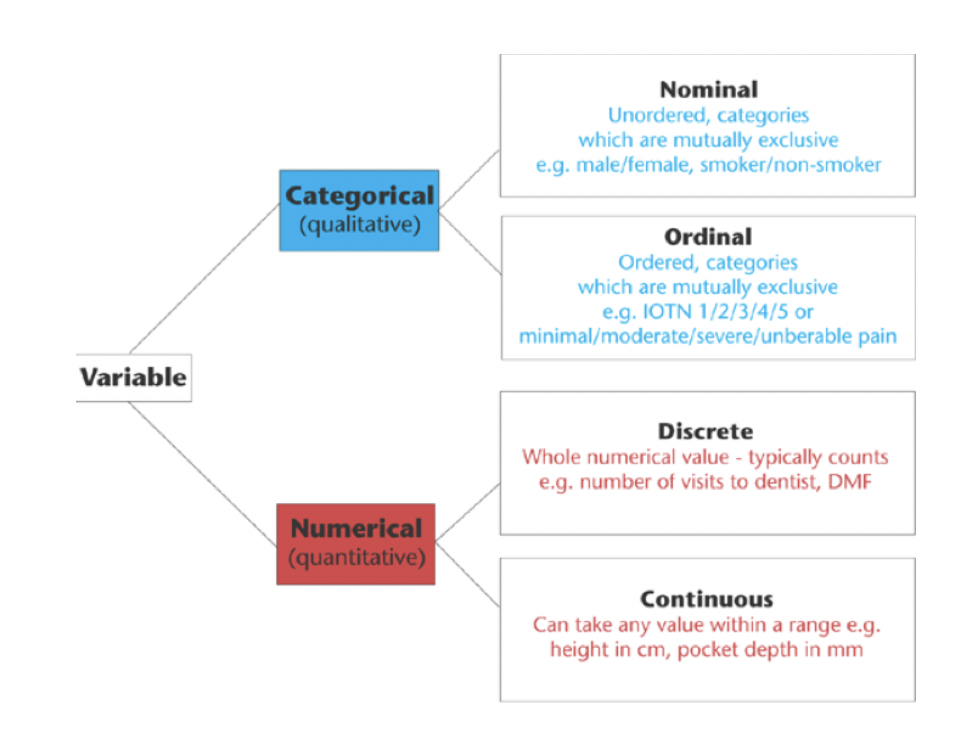
The definitions of distance functions are usually very different for interval-scaled, boolean, categorical, ordinal and ratio variables.
Weights should be associated with different variables based on applications and data semantics.
It is hard to define “similar enough” or “good enough” and the answer is typically highly subjective.
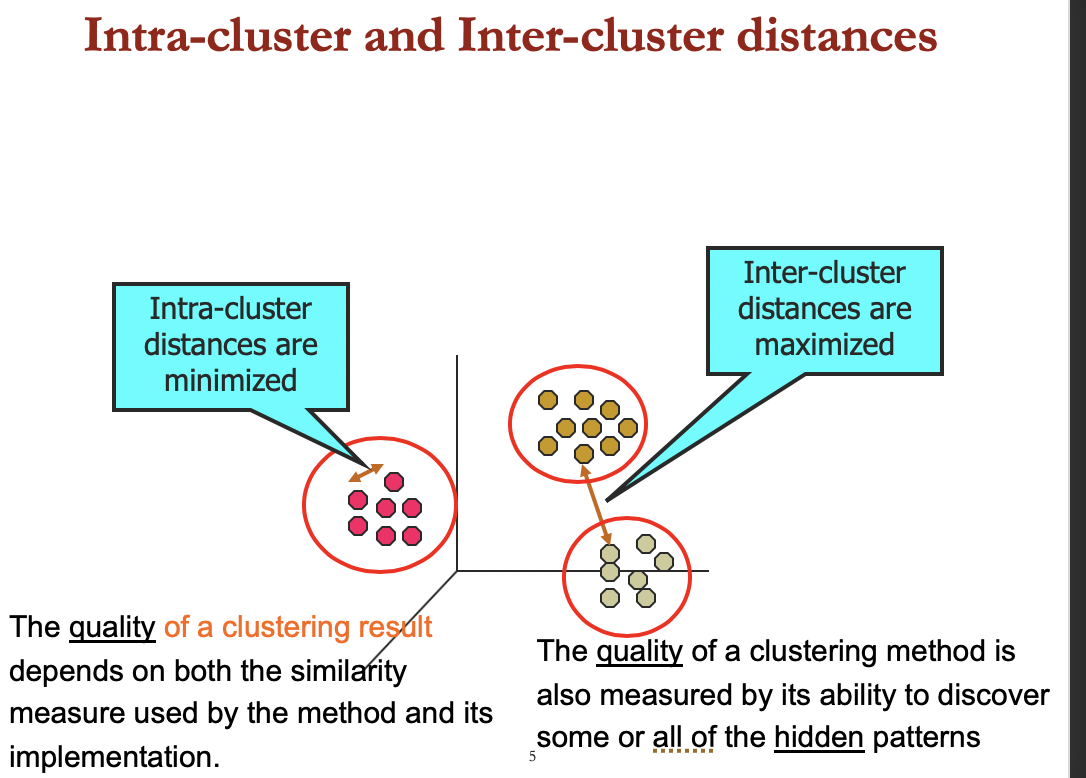
What is Good Clustering?
A good clustering method will produce high-quality clusters with
- high intra-class similarity
- low inter-class similarity
The quality of a clustering result depends on
- the similarity measure used
- implementation of the similarity measure
The quality of a clustering method is also measured by its ability to discover some or all of the hidden patterns
Requirements of Clustering
- Scalability
- Ability to deal with different types of attributes
- Discovery of clusters with arbitrary shape
- Minimal requirements for domain knowledge to determine input parameters
- Ability to deal with noise and outliers
- Insensitivity to the order of input records
- High dimensionality
- Incorporation of user-specified constraints
- Interpretability and usability


Measuring Clustering Quality
Two methods: extrinsic vs. intrinsic
Extrinsic: supervised, i.e., the ground truth is available
Intrinsic: unsupervised, i.e., the ground truth is unavailable